Retrieval Augmented Generation (RAG)
Retrieval Augmented Generation is the process of combining a user's prompt with relevant external contextual information. This process enables LLMs to have more accurate answers, hallucinate less and increases consistency and speed through caching.
LLMs are usually trained on public data, so it cannot know about internal memos of a company or personal emails of an user. It will either not be able to answer or will hallucinate an incorrect answer. RAG would solve this by getting the contextual data necessary and injecting along with the prompt giving the info that the LLM needs to answer properly.
Example
These are 2 cases for a simple scenario where the user asks the LLM what is their name.
Using raw LLM knowledge
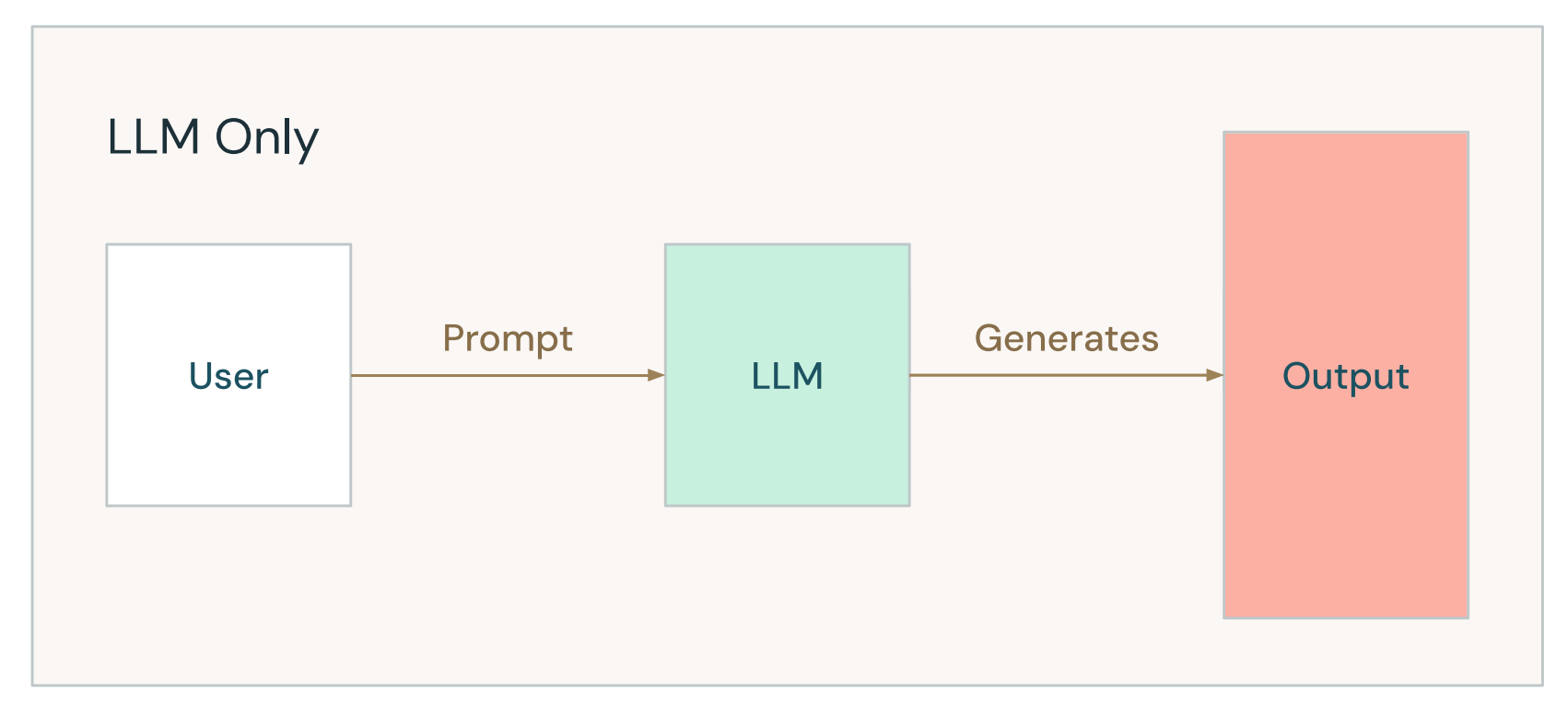
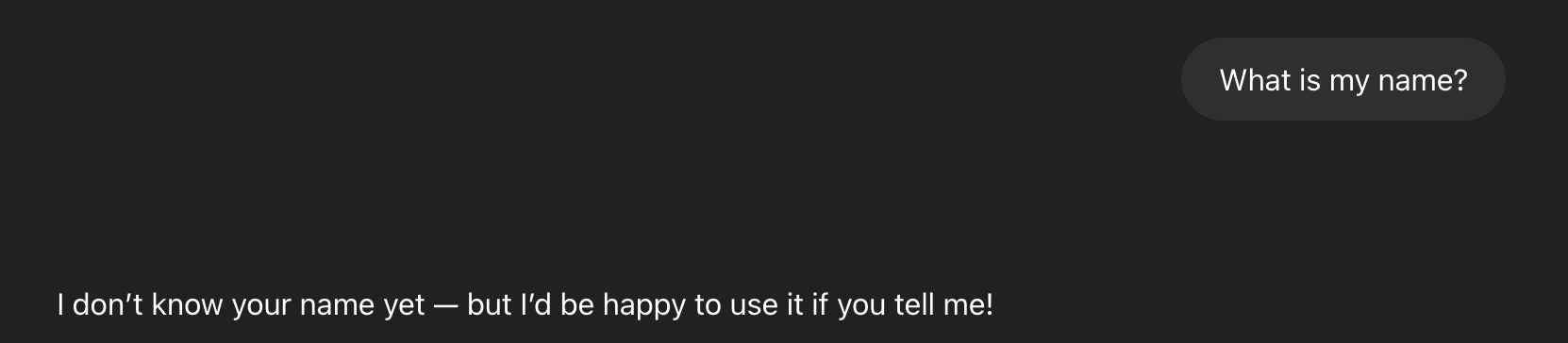
Using RAG
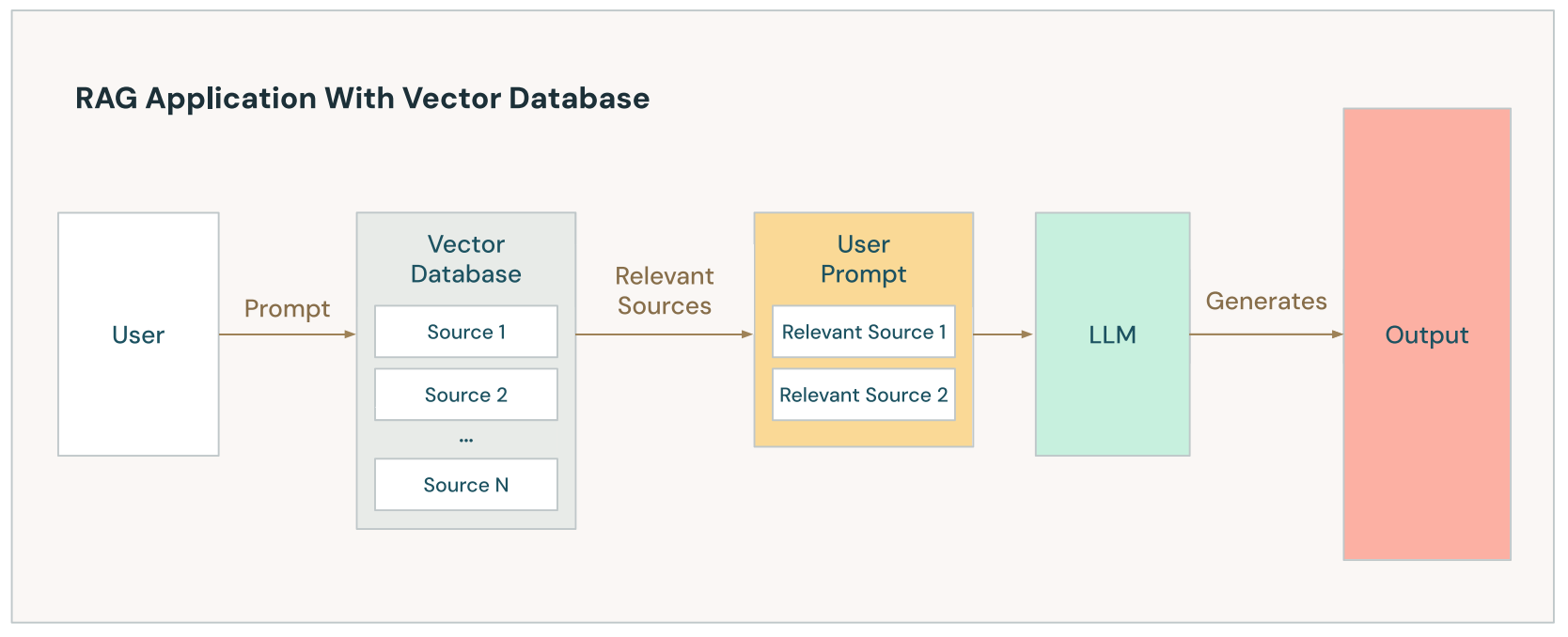
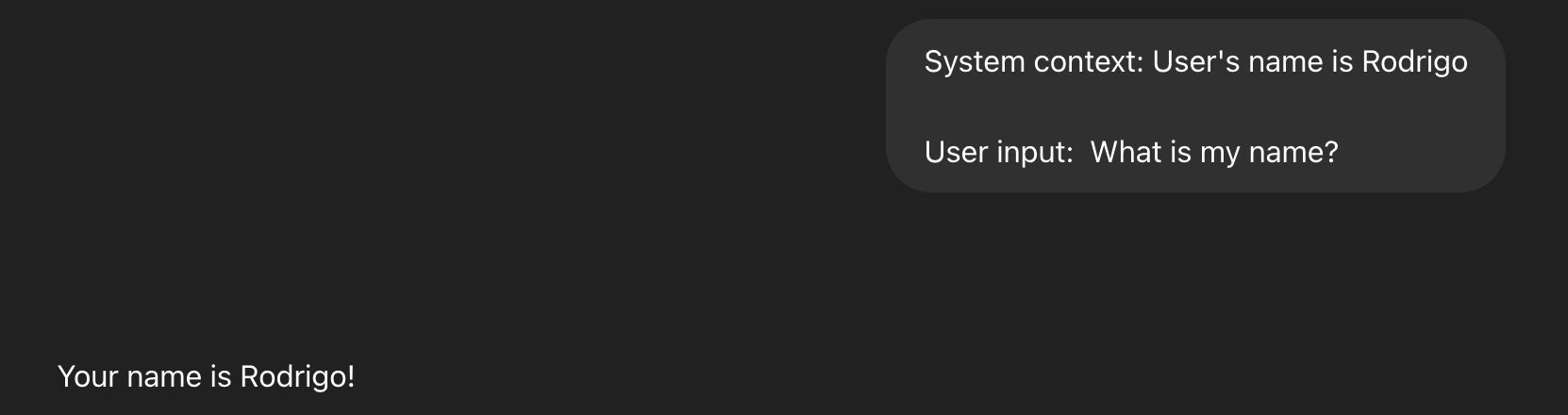
This is an naive example on how it works. For real scenarios the user wouldn't need to input this data manually, because this would be done by the systems that they are using.
RAG can work with many types of data sources such as files, databases, videos and so on, but in most of the content that is currently found on internet it is used with Vector databases.
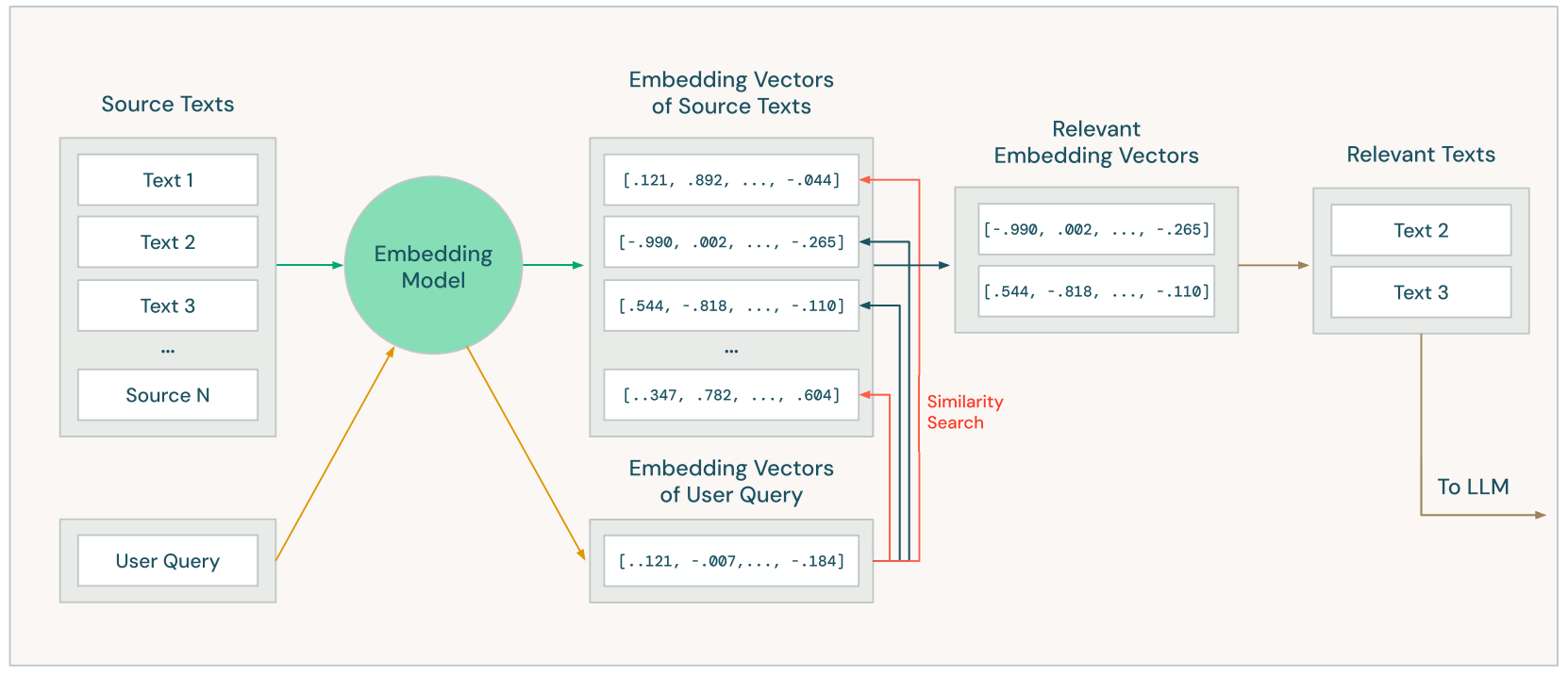
Vector Search and embedding models
Vector search is a type of search that users an special type of language model called an embedding model, that is responsible to translated the text into a numeric vector that represents the text's meaning meaning.
This process is applied both to the data and the user's query, allowing making both content more simple to compare mathematically and thus get relevant results.
RAG Strategies
- Chunking: Dividing documents into smaller, meaningful chunks to improve retrieval accuracy and efficiency.
- Semantic Chunking: Splitting documents based on semantic meaning rather than just fixed sizes or character counts.
- Hybrid Chunking: Combining different chunking methods to balance granularity and context preservation.
- Metadata Enrichment: Adding metadata to chunks to improve retrieval relevance.
- Re-ranking: Employing techniques to re-rank retrieved chunks based on relevance to the query.
- Multi-hop Retrieval: Enabling the system to retrieve information from multiple documents to answer complex queries.
- Contextual Compression: Reducing the amount of retrieved context to focus on the most relevant information.
Sources:
https://www.databricks.com/sites/default/files/2024-05/2024-05-EB-A_Compact_GuideTo_RAG.pdf
https://cdn.prod.website-files.com/61082de7b224bba038edad53/6606beed4962875c7f8297a2_Advanced RAG Techniques Whitepaper WillowTree.pdf