Kafka (CCDAK)
What is Apache Kafka?
Kafka is a distributed streaming platform. This means that kafka enables you to:
- Publish and subscribe to streams of data records
- Store the records in a fault-tolerant and scalable fashion for as long as you need
- Process streams of event as they occur or retrospectively
Kafka is written in java and it was created by linkedin in 2011
Kafka use cases
Messaging - building real-time streaming data pipelines that reliably get data between systems or applications
Kafka is mainly used by 2 types of applications:
- As real-time streaming data pupelines that reliably get data between systems or applications
- As real-time streaming applications that transform or react to the streams of data
Benefits
- Strong reliability garantee
- Fault tolerance
- Robust apis
- Idempotent option
Main concepts and terminology
Events - Also known as record or message, they store information of an event that happened in your applications. An event has a key, value, timestamp and optional metadata headers.
key: alice
value: "Made a payment of 200 to bob"
timestamp: "Jun. 25, 2020 at 2:06 p.m"
Producers - Are applications that publish events to kafka
Offset - A Sequential and unique Id of event in a partition
Consumers - are applications that subscribe to kafka.
Consumer group - By default consumers will re-consume the same records. Consumer groups allow to change this behaviour, allowing for consumers to only consume different events/partitions.
Garantees - There are multiple types of delivery garantees that could be provided:
- At most once - Messages may be lost but never redelivered
- At least once - Messages are never lost but may be redelivered
- Exactly once - Each message is delivered only once
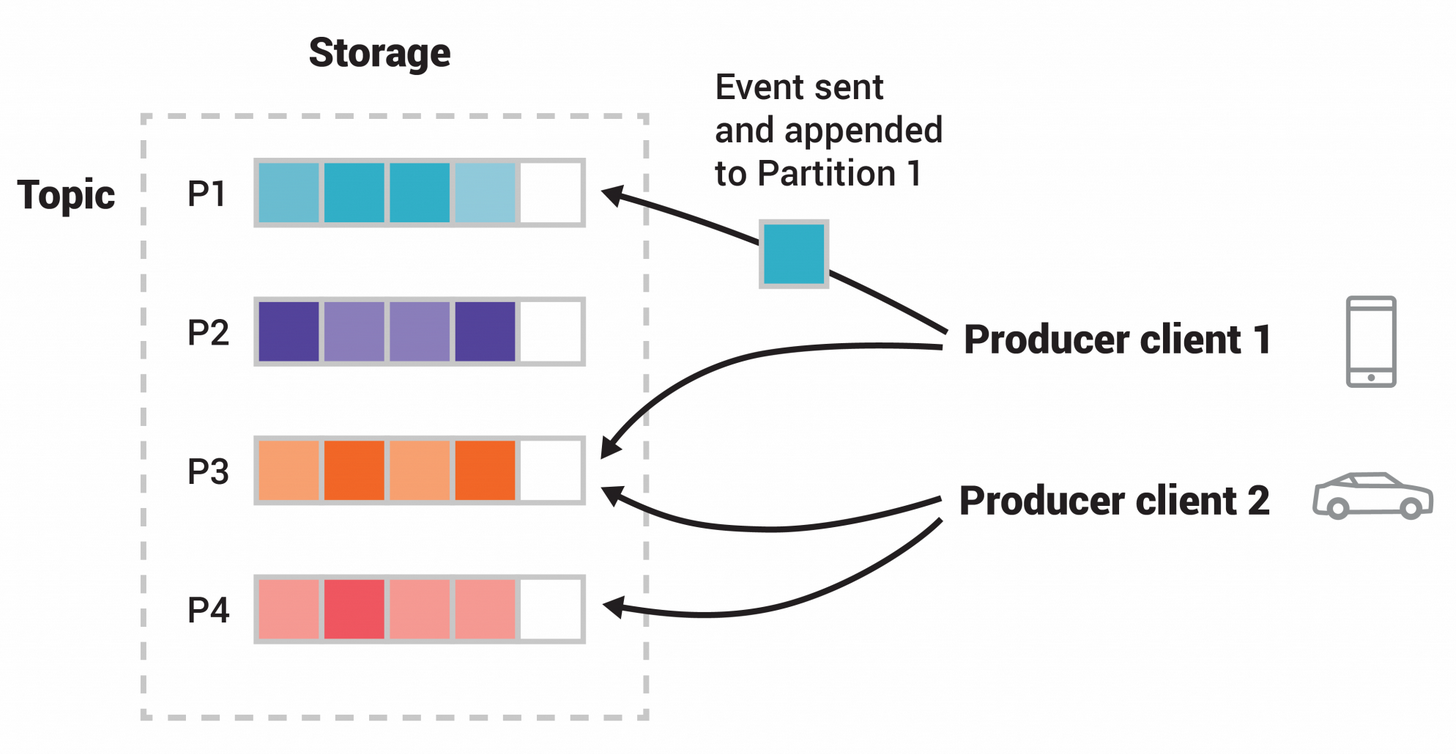
Topics - Events are stored in topics. Topics in Kafka are always multi-producer and multi-subscriber - They can have zero, one or many producers or consumers. Events can be read as often as needed, since they are not deleted on consumption. Deletion is defined by a configuration which defines how long a topic should retain messages.
Partition - Topics are partitioned, meaning that a topic is spread over a number of buckets located in different Kafka Brokers. Wen a new event is published to a topic it is appended to a topic partition. Events with the same key (eg. customer id) are written to the same partition and kafka garantees that consumers will read events in order.
Segment - Files that will handle logs
Log - Immutable and partitioned Data structure used to store a sequence of events
Replication - To make your data fault tolerant and highly available every topic can be replicated in different brokers. A common configuration is a replication factor of 3.
Producers Garantees
- Acks 0 (None) - The producer will send the message and won't wait for an ACK. This can cause data loss, but will have less latency for the producer.
- Acks 1 (Leader) - The producer will only wait the leader's ACK
- Ack -1 (all) - The producer will wait all brokers that own the partition affected to ACK
Compacted Topics?
Architecture
Brokers are servers that make a Kafka Cluster. Producers and consumers communicate with them to publish and consume messages.
Kafka depends on zookeeper to manage clusters. It coordinates cluster communication, adds, removes and monitor brokers/nodes.
Kafka elects a broker to be the Controller, which coordinates assigning partitions and replicas to other nodes. If the controller goes down another one will be elected.
Kafka uses TCP to handle message communication
Design
https://kafka.apache.org/documentation/#design
Partitions and replication
A partition is assigned to an specific broker and to achieve fault tolerance this partition is replicated to other clusters. The replication factor is the number of replicas that will kept in different brokers.
To ensure consistency kafka chooses a leader for each partition, the leader handles all reads and writes for the partition. If the leader is down the cluster tries to choose a new one by leader election.
By default Kafka will only set as electable replicas that are in sync (ISR), if there are no ISR Kafka will just wait until one becomes available. It is possible to configure this behaviour so it will work as unclean leader election.
Kafka Streams
Work as Node.js Transformation streams (get an input and pipe to an output).
There are 2 types of transformations in Kafka Streams:
- Stateless transformations - Do not require any additional storage to manage state (1 record at a time)
- Stateful Transformations - require a state store to manage the state (needs historical data)
Stateless Transformations
- Branch - Splits a stream into multiple streams based on a predicate
- Filter - Removes messages based on condition
- FlatMap - Takes events and turns into different set of records
- ForEach - Terminal operation
- GroupBy/GroupByKey
- Map - Map to another format
- Merge - Merges 2 streams into one
- Peek - Similar to foreach but does not stop processing
Stateful Transformations
- Agregate - uses Groupby/groupbykey to aggregate/count/reduce
- Join - Similar to merge but join things as a SQL join (Inner join, left join, outer join)
Kafka Configuration
- Read-only - Needs to restart the cluster
- Broker-wide - Applies only for an specific broker
- Cluster-wide - Applies to the whole cluster but doesn't need to restart it.
Topic Design
Kafka connect?
Debezium?